Python目前貌似没有直接解析Markdown文件的库,一般只有提取库,就是只能从Markdown文件中批量提取图片,基本原理都是要把Markdown渲染成html,再解析html拿到img标签内的图片路径,但如果需要修改markdown图片的路径,貌似没有现成的库。
我目前的方案是直接读取markdown里面的所有内容,然后用正则表达式来提取和批量替换。
简要说明
我的文件结构如下:
markdown文件和图片是分开存放的
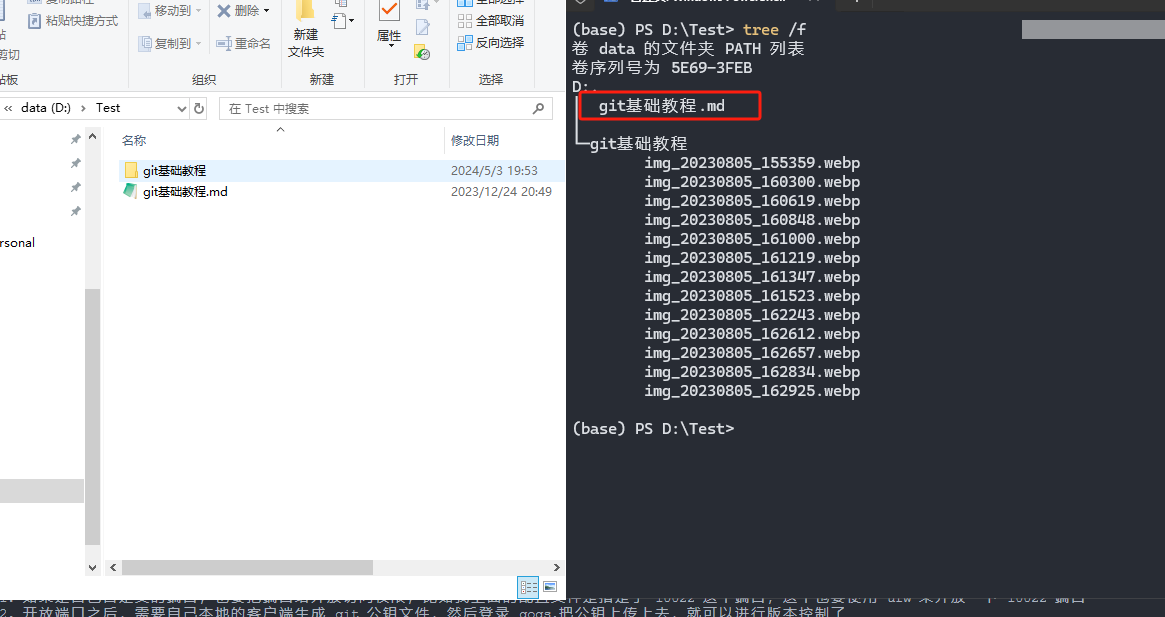
但我的markdown文件的内容里面的链接并没有正确写入相对链接:
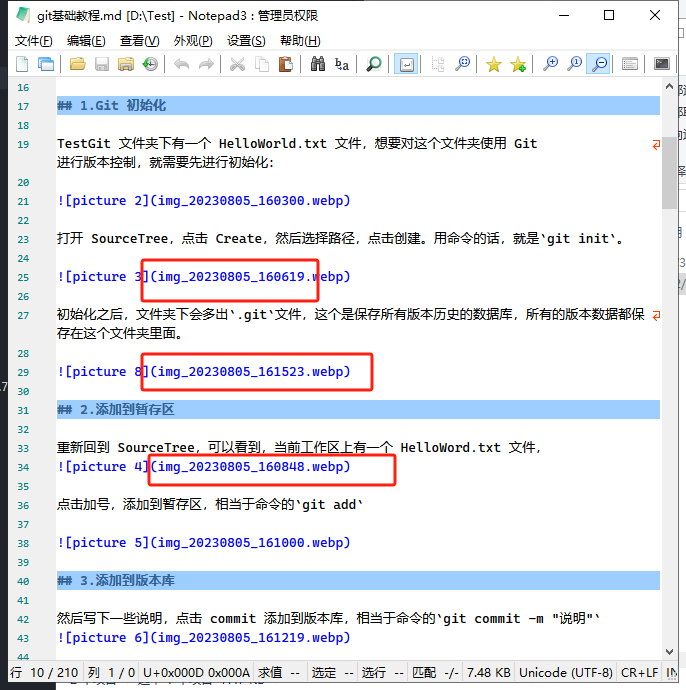
也就是说,现在的路径是错的,如果我用markdown编辑器打开,比如marktext,显示效果如下:
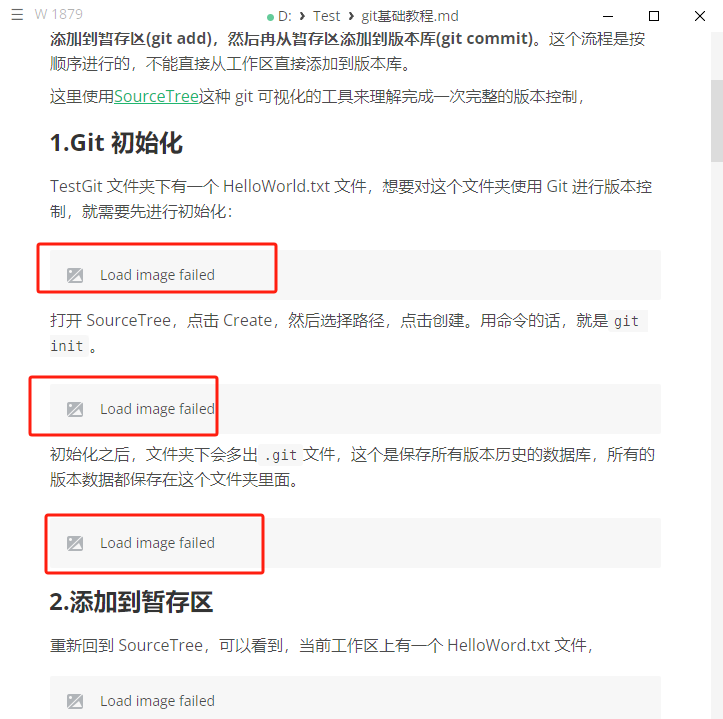
现在需要批量把这个路径修改成正确的路径。
如果只有单个文件,当然直接就查找替换就行了,多个文件的时候才可能需要用到这种批量替换
解决方案
这里我使用的是python,没有引入第三方库,都是原生的系统库,因为这只是一个简单的正则表达式,字符串替换,文件操作而已。
接下来上源码
"""
图片正则: !\[.*?\]\(.*?\)
1. 先用正则批量,找出所有图片
2. 把图片要替换成的最终结果,保存到字典里面,key代表旧,value代表新值
3. 再重新遍历整个文档内容,直接匹配替换,不要正则
4. 最后写入文件
"""
import re
import os
def ImgAddPreffix(mdFile, prefix):
"""图片添加前缀链接
Parameters:
mdFile - markdown文件路径
prefix - 要给img路径添加的前缀
Returns:
返回替换好的markdown内容
"""
with open(mdFile, "r", encoding="utf-8") as f:
content = f.read()
dicts = {}
# 先找到所有的图片,比如
pattern = r"!\[.*?\]\(.*?\)"
matchImgs = re.findall(pattern, string=content)
# 遍历每个图片
for img in matchImgs:
# 匹配链接部分:即匹配里面的,xxx.png
# 这里imgLink的值会得到xxx.png
imgLink = re.findall(r"\((.*?)\)", img)[0]
# 添加图床链接前缀,result最后会变成 
newImgLink = prefix + imgLink
result = re.sub(imgLink, newImgLink, img)
# 先保存起来,key是旧的值,value是新的值
dicts[img] = result
# 替换内容
for oldValue, newValue in dicts.items():
content = content.replace(oldValue, newValue)
return content
def WriteContent(mdFile, content):
"""
把修改好的内容写入新文件里面,新文件名为: 原文件名_publish.md
"""
fileName = os.path.basename(mdFile).split(".")
dupMdFileName = f"{fileName[0]}_publish.{fileName[1]}"
dupMdPath = os.path.join(os.path.dirname(mdFile), dupMdFileName)
with open(dupMdPath, "w") as f:
f.write(content)
if __name__=="__main__":
mdDir = r"D:\Test"
prefix = "git基础教程/"
for root, dirs, files in os.walk(mdDir):
for f in files:
if not f.endswith(".md"):
continue
fPath = os.path.join(root, f)
content = ImgAddPreffix(fPath, prefix)
WriteContent(fPath, content)
运行一下这个脚本,自动生成了一个publish后缀的副本,上面已经修改好图片的路径
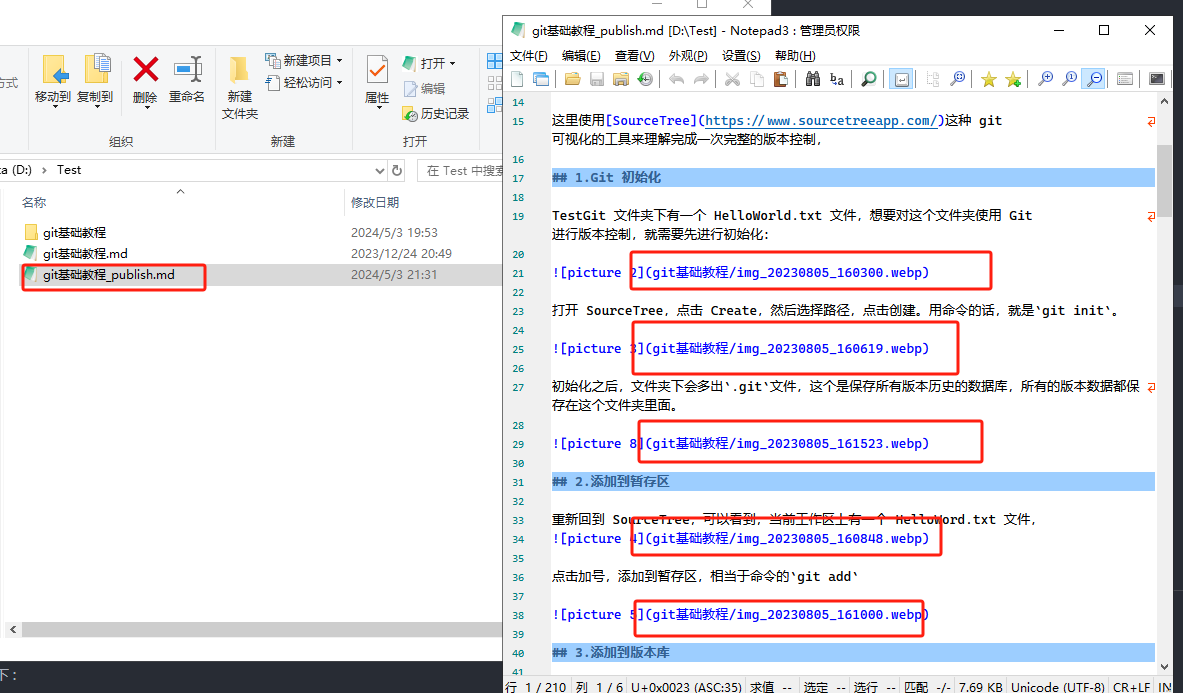
打开查看一下:
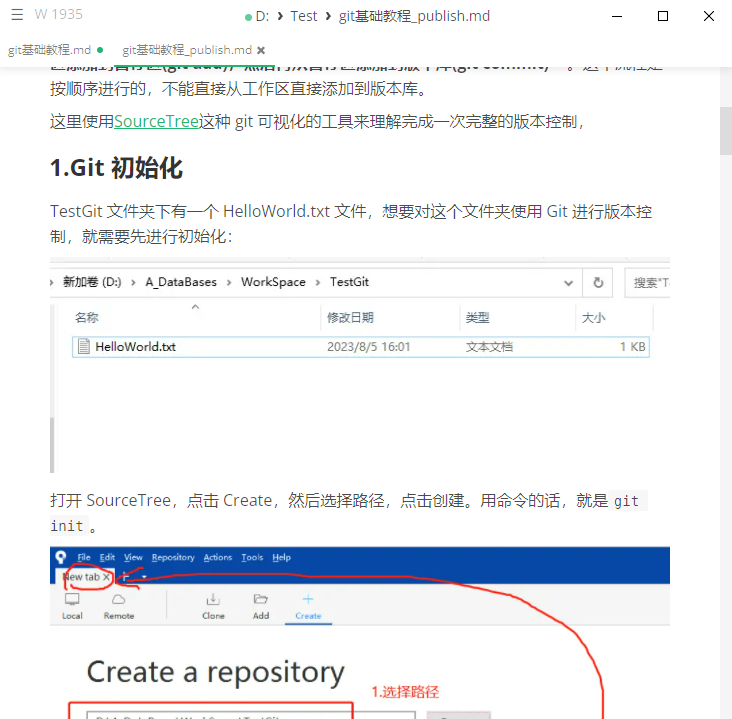
OK,显示正常。




